BookBrainz Schema¶
Introduction¶
The BookBrainz schema describes how the data used by BookBrainz is stored. It’s quite important to have a good idea of this before you look at any of our code. If you’re coming from a MusicBrainz background, our schema is similar, but there are some key differences - see Coming from MusicBrainz.
Overview¶
In BookBrainz, an entity is a container for some data, associated with some globally unique identifiers (GIDs). BookBrainz represents a number of different objects as entities, and each of these has its own particular associated data. In the following section, we’ll go through the database structures used to represent entities, and talk about each type of entity in more detail.
Entities¶

There are 6 entity types in the BookBrainz world: Author, Work, Edition Group, Edition, Publisher and Series.¶
- Author
- An individual, group or collective that participates in the creative process of an artistic work.It also includes translators, illustrators, editors, etc.
- Work
- A distinct intellectual or artistic creation expressed in words and/or images.Here we are not talking, for example, about a physical book, but the introduction, story, illustrations, etc. it contains.Examples: novel, poem, translation, introduction & foreword, article, research paper, etc.
- Edition
A published physical or digital version of one or more Works. Examples: book, anthology, comic book, magazine, leaflet .. note:: An Author can self-publish an Edition
- Series
- A set or sequence of related works, editions, authors, publishers or edition-groups.Examples: a series of novels, a series of comics, etc.
- Edition Group
A logical grouping of different Editions of the same book. Example: paperback, hardcover and e-book editions of a novel
- Publisher
A publishing company or imprint
Entity and Entity Redirect¶
All entity GIDs are stored in a single table in the database, entity.
A second table, entity_redirect, allows redirection of GIDs. For example, if one entity was merged into a second entity, then a row would be created in the entity_redirect table to indicate a mapping to the merge target.
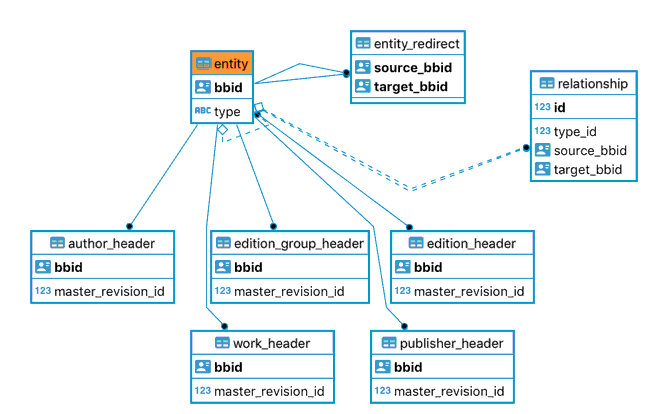
The entity table and its relationships¶
Versioning¶
Entities in BookBrainz are versioned, which means that the entire entity history is stored in the database. To make this possible, we have a number of additional tables in the database. For an explanation, let’s take the example of an Author entity.
The entity table, common to all entity types, describes the BBID (unique identifier, will never change) and type of an entity.
Each entity type has its own _header and _revision tables, in this case author_header and author_revision.
The author_header table tells us what is the master –or latest– revision of that Author entity
The author_revision entry points to the author_data table representing the state of that entity at that revision.
Each time a user modifies one or more entities, a new revision is created for each entity modified.
That includes adding or modifying a relationship between two entities.
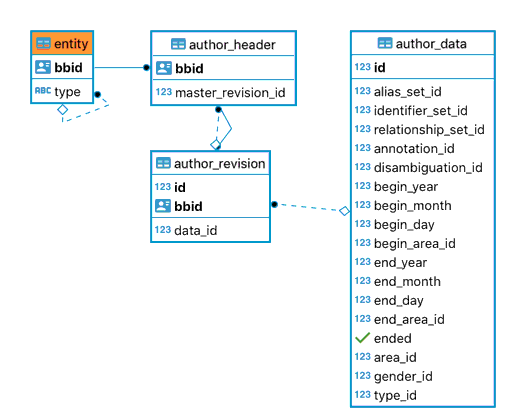
The main tables for Author entities¶
Revisions¶
A revision represents a set of changes to one or more entities.
If you change an Author’s date of birth, your revision will have the same ID as one single author_revision, which represents the state of that entity at that time.
If for example you create a relationship between an Author and a Work (“Author X wrote Work Y”), you will have a single revision
but you will find an author_revision AND a work_revision with the same ID as the revision.
This tells us that unit of change concerns the two entities, and each *$entity*_revision represents that entity’s state after that change.
Following me so far?
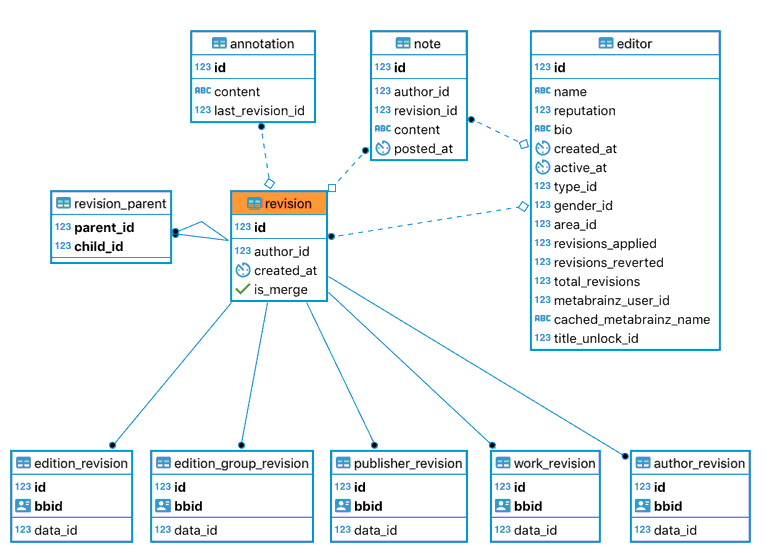
The revision table and associated tables¶
Entity revision¶
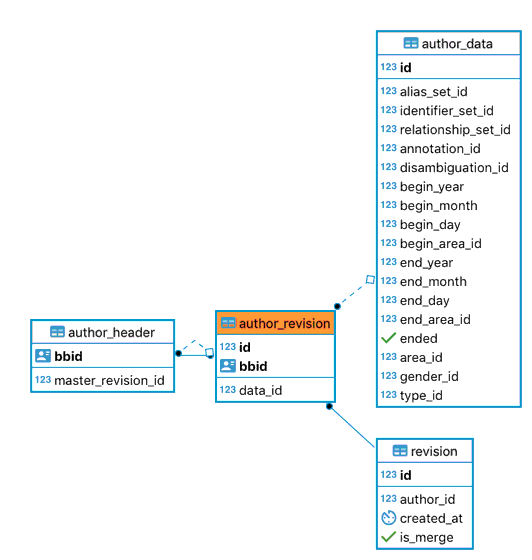
An author_revision in action¶
As we saw above, a change to an Author will create a new author_revision which contains a data_id column. This ID links to an entry in the author_data table that describes the state of that entity.
Revision parent¶
The revision_parent table allows us to reconstruct the history of all the edits that have changed an entity,
inspect it at any given time, and even revert past edits.
When a new revision is created, it stores a reference to the previous revision.
For merge revisions, it will store a reference to the revisions of each entity being merged.
Entity data¶
Some of the information is stored directly in that author_data table, and some other information are stored separately.
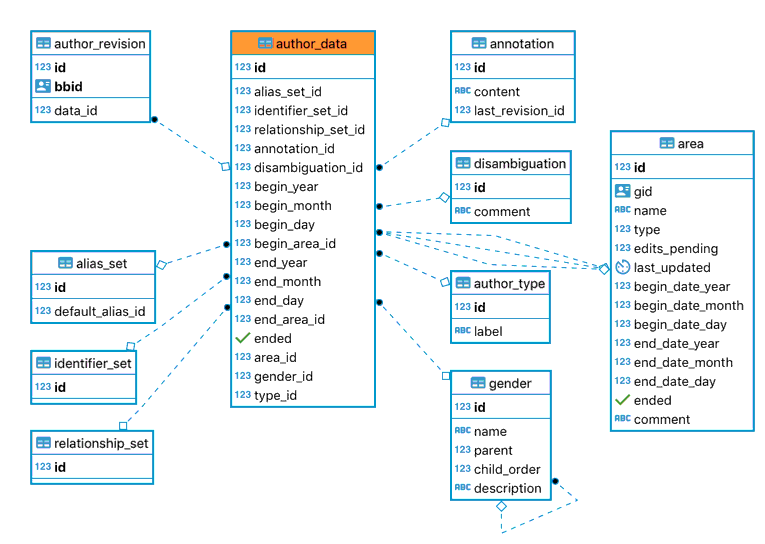
Overview of the author_data associated tables¶
Sets¶
Each entity uses sets to represent groups of items: aliases (or names), identifiers (ID of that entity in other systems like wikidata), relationships, languages, etc. Sets allow us to modify some data while keeping the rest untouched, which is necessary for our versioning system. For example deleting an item from a set will create a new set but the removed element still exists and is still part of the previous set.
Each set type is comprised of three tables:
XXXXX: the table of elements of type XXXXX (for example
alias)XXXXX_set: the table of sets of type XXXXX (for example
alias_set)XXXXX_sets_XXXXX: the table that links elements to a specific set (for example
alias_set__alias)
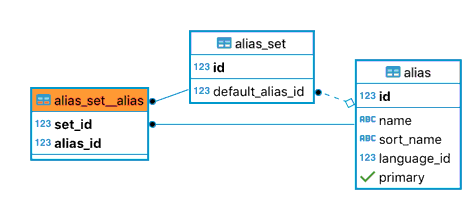
An alias and the set it belongs to¶
Alias sets¶
Aliases are stored each separately, and combined to form an alias_set. This represents the various names of an entity. For example, an Author could have their birth name, a pen name, their name in various other languages, etc. There is a default_alias_id stored for each alias_set that points to one alias, as a shortcut if you only needs the main name of an entity.
When an alias is added to an entity, a new alias_set is created that will contain the previous unchanged aliases as well as the new alias.
If an existing alias is modified, a new alias entry will be created as well as a new set containing that new alias entry. That means if we want to revert the change, the previous revision contains a reference to the previous alias_set that contains the original alias.
You will find the same structure for identifier sets and relationship sets.
Identifier sets¶
Identifiers represent the ID of the entity in another system (wikidata, musicbrainz, openlibrary, etc.). An entity can have an identifier set, represented by an id linking to row in the identifier_set__identifier table, which links a set to the identifiers that comprise it. That way, when adding a new identifier, a new set is created but the existing identifiers are not modified.
The set is comprised of identifiers each of a type_id that refers to the identifier_type table. The entity_type must correspond to the Entity’s type. The other columns of identifier_type are used for detecting and displaying purposes on the front-end and API.
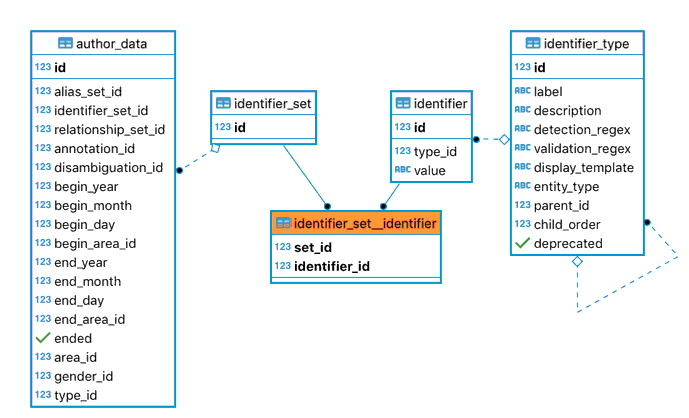
Relationship sets¶
Relationships are of a specific type (a relationship_type referred to by id) that describes the relationship, the entity type expected on either side of the relationship, and the phrases to use to represent the relationship from either direction (i.e: “Author X wrote Work Y” and “Work Y was written by AuthorX”).
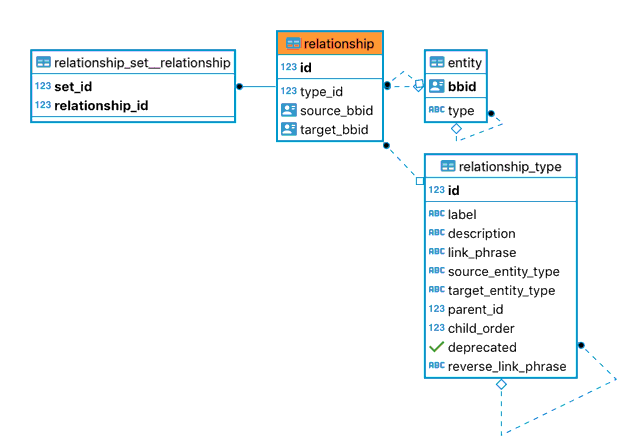
A relationship set contains relationship entries¶
Publisher sets and release event sets¶
These sets are used solely for the Edition entities
The publisher sets don’t have an associated publisher table like other sets.
Instead, the publisher_set__publisher table links a publisher_set to the BBID of a Publisher entity
Additional Tables¶
There are some additional tables related to all types of entity. We’ve already mentioned annotations and disambiguations, so let’s talk a little more about those.
An annotation is a way of making notes about an entity, for other editors to read. It stores some content associated with an ID. Disambiguation comments, stored in the disambiguation table, have a similar data structure but are intended to contain a short description to allow editors to easily differentiate between similarly-named entities.
An alias represents a name or title. Each alias will store some text along with a language, and a couple of flags to indicate whether the alias is primary and whether it is native. An entity can only have one native alias, which indicates its original name. It can have many primary aliases, which give the most common names in particular languages. Native aliases will usually also be primary.
A disambiguation allows us to differentiate between two entities with the same name. All entities can have a disambiguation (although they are not required), referred to by a disambiguation_id, that points to the disambiguation table.
Author credits¶
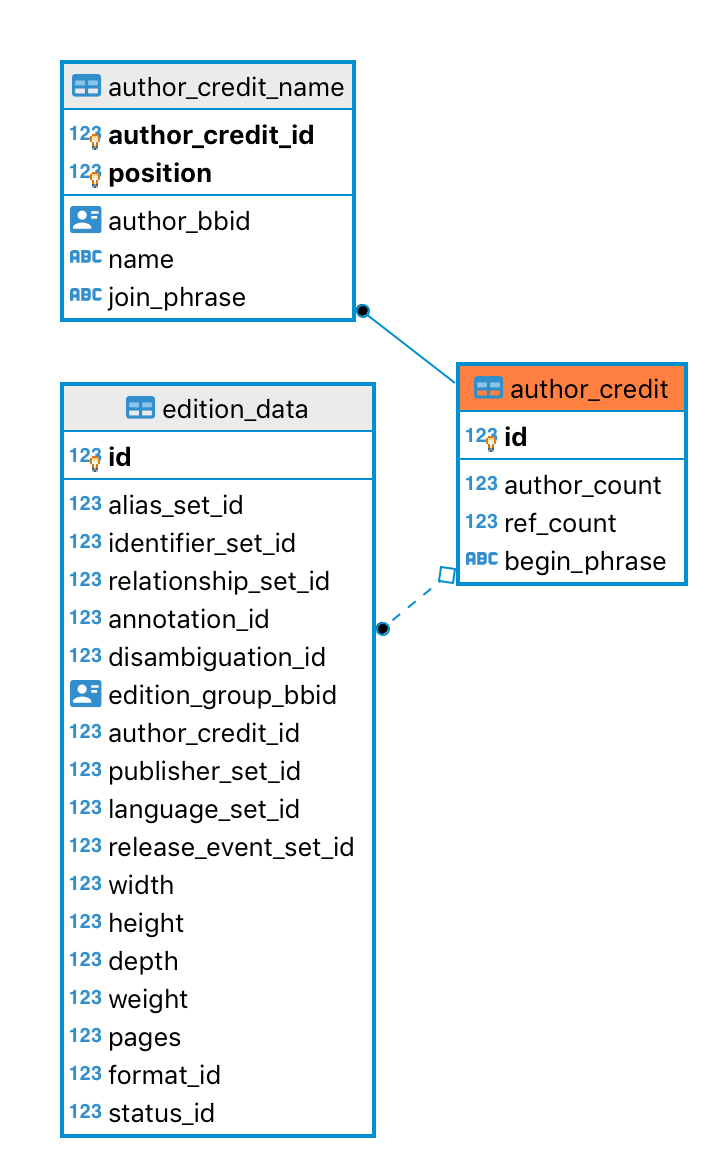
Author credits allows us to define how authors are credited in an Edition (as on the book cover), without having to create separate Author entities for each pen name or name variation.
For example, Howard Phillips Lovecraft published under the names “H.P. Lovecraft” most notoriously, but you will find some Editions use the full name “Howard Phillips Lovecraft”
The author credits are composed of one or more authors. For each author, an author_credit_name is created with the author’s BBID, name as credited and position, as well as a short phrase to join them with the next author.
For example if a book cover features “by John and Jane Doe”, you would enter: Position 1: John Doe’s BBID - name: “by John” - join phrase “and ” Position 2: Jane Doe’s BBID - name: “Jane Doe”